모두의 딥러닝이라는 책을 읽으면서 정리하였습니다.
딥러닝 활용 전 내용까지 정리하였고 정신건강을 위해 수식은 생략하였습니다.
Deep Learning Study
1. 모두의 딥러닝
1장. 첫 딥러닝
-
딥러닝의 개괄 잡기
-
크게 데이터 분석과 입력, 딥러닝 실행 부분으로 나뉜다.
1) 데이터 분석과 입력
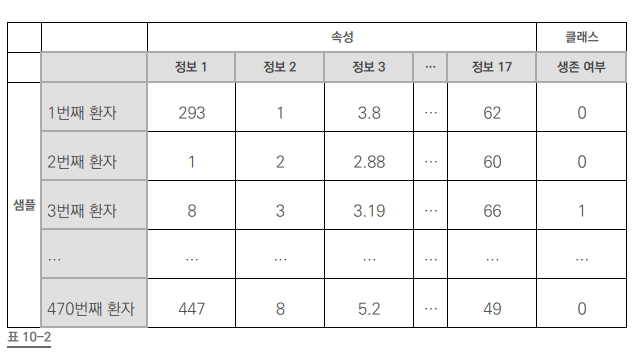
# 불러온 데이터를 적용합니다. my_data = 'ThoraricSurgery.csv' Data_set = np.loadtxt(my_data, delimiter=",") # 환자의 기록과 수술 결과를 X와 Y로 구분하여 저장합니다. X = Data_set[:,0:17] # attribute (속성) Y = Data_set[:,17] # class (클래스)2) 딥러닝 실행 부분
tensorflow : 비행기, keras : pilot 이라고 이해
# 딥러닝을 구동하는 데 필요한 케라스 함수를 불러옵니다. from tensorflow.keras.models import Sequential # 딥러닝 구조를 한층 한층 쌓게 해준다. from tensorflow.keras.layers import Dense # 각 층이 제각각 어떤 특성을 가질지 정해준다. # 딥러닝 구조를 결정합니다(모델을 설정하고 실행하는 부분입니다). model = Sequential() model.add(Dense(30, input_dim=17, activation='relu')) model.add(Dense(1, activation='sigmoid')) # 딥러닝을 실행합니다. model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(X, Y, epochs=100, batch_size=10)-
activation : 다음 층으로 어떻게 값을 넘길지 (relu와 sigmoid 함수를 많이 씀)
- loss : 오차 값을 추적하는 함수
- optimizer : 오차를 어떻게 줄여 나갈지 정하는 함수
-
-
딥러닝을 위한 기초 수학
1) 기울기, 편미분, 로그, 로그함수, 시그마는 기본으로..
2) 시그모이드 함수
- 큰 값을 가지면 1에 가까워지고 작은 값을 가지면 0에 가까워 지는 함수 (S 자형)
- 0 또는 1, 참 거짓 판단 할때 유용하게 쓰인다.
-
2장. 딥러닝의 동작원리
가장 기본, 말단에서 이루어지는 두가지 원리를 알아야 한다.
선형 회귀, 로지스틱 회귀
선형 회귀
-
선형 회귀 (Linear Regression)
1) 정의
- y = ax + b (y는 종속 변수, x는 독립 변수)
- x 값이 하나이면 단순 선형 회귀, 여러 개이면 다중 선형 회귀
2) 가장 훌륭한 예측선?
-
최적의 a, b 값을 찾는 선
따라서, a와 b를 찾자!
3) 최소 제곱법 (Method of Least squares)
- a와 b를 구하기 위한 공식
- 그럼에도 오차가 존재
4) 평균 제곱 오차(Mean Square Error, MSE)
- 오차를 평가
- 계산의 결과가 가장 작은 선을 찾아야 한다.
- 경사 하강법 (오차를 수정하자)
1) 경사 하강법 개요
-
반복적으로 기울기를 변화 시켜 최솟값 m을 찾는다. (기울기가 0일 때 최소가 되겠지)
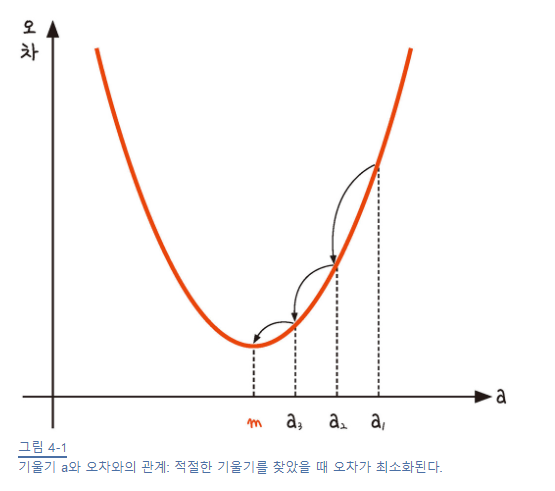
2) 학습률
-
기울기 부호를 바꿔 이동시킬 때 적절한 거리를 찾지 못해 너무 멀리 이동시키면 한 점으로 모이지 않는다.
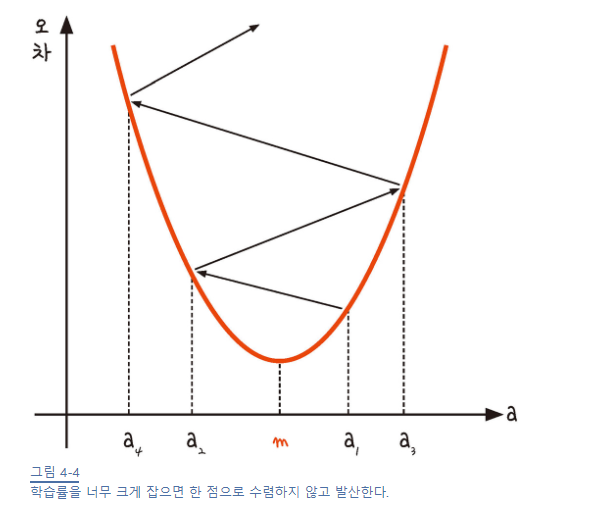
-
학습률의 값을 바꾸면서 최적의 학습률을 찾는 것은 중요한 최적화 과정 중 하나
- 에포크 (epoch) : 입력 값에 대해 몇 번이나 반복하여 실험했는지
경사 하강법은 오차의 변화에 따라 이차 함수 그래프를 만들고 적절한 학습률을 설정해 미분 값이 0인 지점을 구하는 것 -
다중 선형 회귀
-
더 정확한 예측을 하려면 추가 정보가 필요할 것이고
변수의 개수를 늘려 다중 선형 회귀를 만들자.
-
로지스틱 회귀(Logistic Regression)
Yes or No
-
시그모이드 함수
a와 b값에 따라 오차가 변하고
a와 b를 구해야 하는데 이를 구하려면 경사하강법을 사용해야겠지
시그모이드 특징을 이용하자! (y값이 0과 1사이)
실제값이 1일때 예측 값이 0에 가까워지면 오차가 커지고, 실제값이 0일때 예측 값이 1에 가까워지는 경우에도 오차는 커진다.
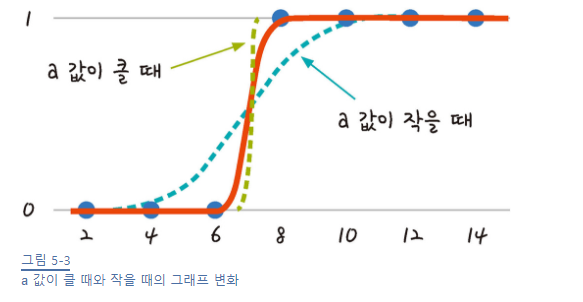
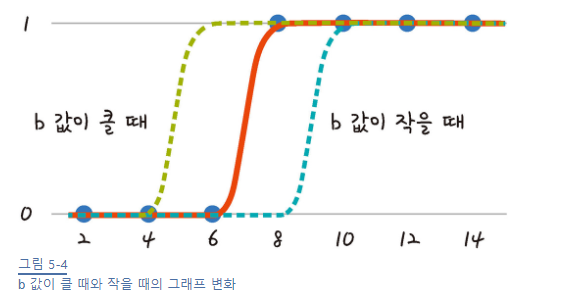
이를 공식으로 만드는 함수가 로그함수!
-
로그함수
정리하면.. 로지스틱 회귀를 위해서 시그모이드 함수를 사용한다는 것! 0과 1사이의 값을 가지는 특성 때문에 로그 함수를 함께 쓰자는 것! 경사 하강법을 이용해 a와 b의 최적 값을 찾자!
경사 하강법할때 편미분 이용해야 해…
-
소프트맥스(Softmax) 함수
만약 입력값이 여러개라면 시그모이드 함수가 아니라 소프트맥스 함수를 써야 한다.
총 합을 1로 만들어 큰 값은 두드러지게 작은 값은 더 작아지게 만들자!
로지스틱 회귀에서 퍼셉트론으로
y = a_1 * x_1 + a_2 * x_2 + b
x1과 x2가 입력되고, 각각 가중치 a1, a2를 만나며 여기에 b를 더한 후에!! 시그모이드 함수를 거치면
1과 0의 출력 값 y가 만들어진다! ==> 퍼셉트론 이론
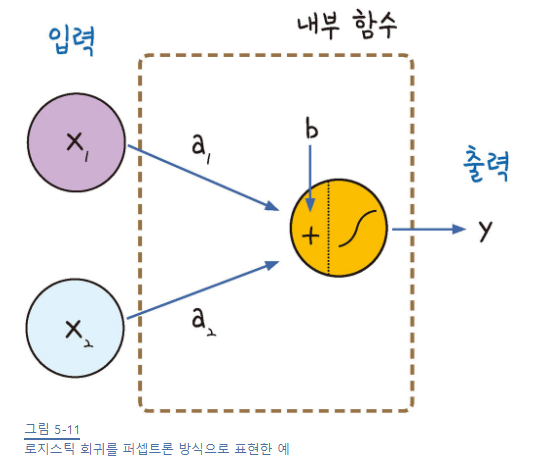
퍼셉트론 이론 =====> 인공 신경망, 오차 역전파 ====> 딥러닝
3장. 신경망의 이해
퍼셉트론으로 이루어진 신경망의 내부를 들여다 보자.
지금의 딥러닝으로 있게 한 신경망에 대한 이해, 단점을 극복하게 해 준 오차 역전파 이론,
딥러닝의 가장 중요한 이론적 배경을 배운다.
퍼셉트론
입력 값을 놓고 활성화 함수에 의해 일정한 수준을 넘으면 참, 그렇지 않으면 거짓을 내보내는 매커니즘
뉴런과 비슷하다! 뉴런이 연결되면 그 결과는 우리의 ‘생각’
뉴런과 비슷한 메커니즘을 사용하면 인공적으로 ‘생각’하는 그 무엇인가를 만들 수 있지 않을까?
따라서, 신경망의 기본 구조
여러 층의 퍼셉트론을 서로 연결시키고 복잡하게 조합하여 주어진 입력 값에 대한 판단을 하게 하는 것!
-
가중치, 가중합, 바이어스, 활성화 함수
y = wx + b (y : 가중합, w : 가중치, x : 입력값, b : 바이어스)
여기서 y의 값 즉, 가중합의 결과를 1 또는 0으로 판단하는 함수 ==> 활성화 함수(Activation Function)
대표적으로 시그모이드 함수겠지
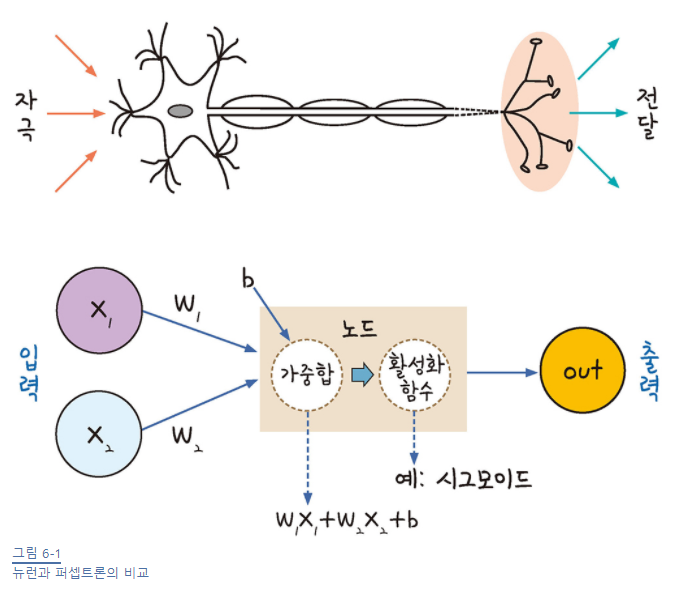
-
퍼셉트론의 과제
선으로는 같은 색끼리 나눌 수 없다.
즉, 직선을 그어서 분류를 할 수가 없다.
-
XOR 문제
퍼셉트론의 한계를 설명할 때 등장!
둘 중 하나만 1일때 1이 출력되는 논리 회로 XOR 로는 결과를 나눌 수 없다.
이를 해결한 개념이 바로 다층 퍼셉트론!! (이게 약 10년 후에 발표됬다는데…)
다층 퍼셉트론
XOR 문제를 해결하기 위해 좌표 평면 자체에 변화를 주면 되지 않을까?
그러면 직선을 그을 수가 있다!
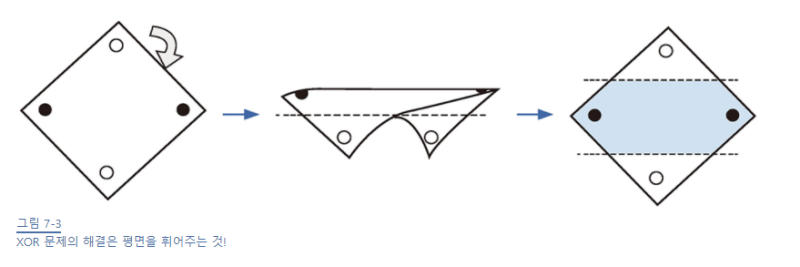
따라서 은닉층(숨어있는 층)을 만들자.
-
다층 퍼셉트론의 설계
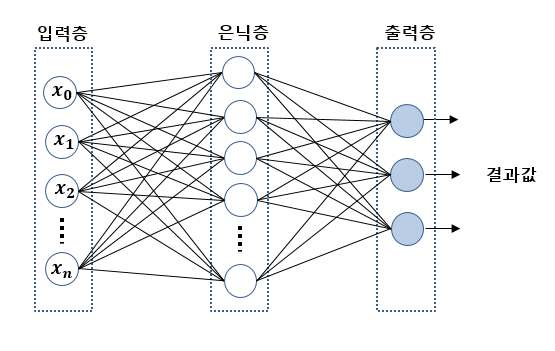
-
인공 신경망
은닉층을 여러 개 쌓아올려 복잡한 문제를 해결하는 과정은 뉴런이 복잡한 과정을 거쳐 사고를 낳는 사람의 신경망을 닮았다.
이를 줄여 신경망이라고 통칭
오차 역전파
신경망 내부의 가중치는 어떻게 수정하나?
오차 역전파 방법 이용 (경사 하강법의 확장 개념)
-
오차 역전파의 개념
가중치를 구하기 위해서 경사 하강법을 이용하면 될텐데 어떻게 구할까?
단일 퍼셉트론을 생각해보면?
결과값과 오차를 구해 가중치를 구했다.
이와 마찬가지로 다층 퍼셉트론도 결과값의 오차를 구하면 되겠지?
층이 여러개 있으니 여러번 거슬러 올라가면 될듯!
최적화 계산 방향이 출력층에서 시작해 앞으로 진행( 거꾸로)
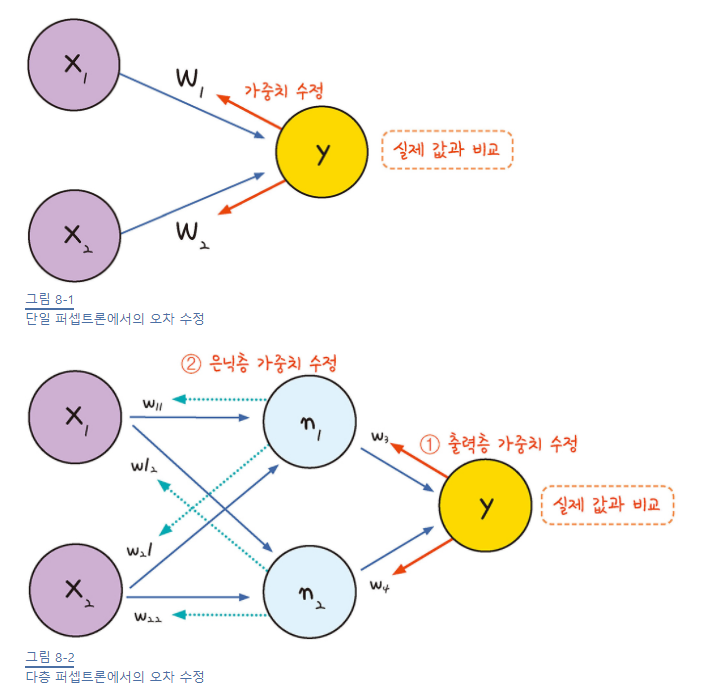
-
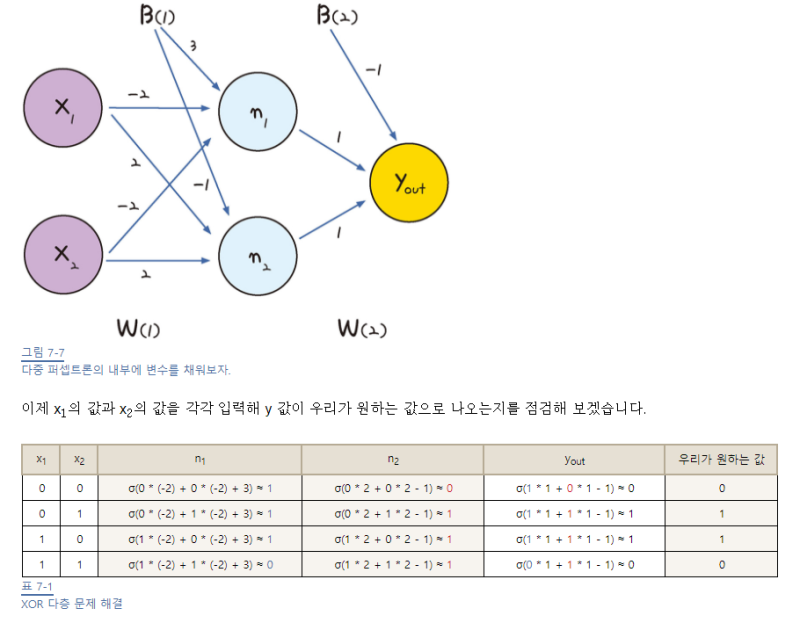
오차 역전파 구동 방식
1) 임의의 초기 가중치(W) 를 준 뒤 결과(Y)를 계산
2) 계산 결과와 원하는 값 사이의 오차 계산
3) 경사 하강법을 이용해 바로 앞 가중치를 오차가 작아지는 방향으로 업데이트
4) 더이상 오차가 줄어들지 않을 때까지 반복
- 오차가 작아지는 방향으로 업데이트 한다 = 미분 값이 0에 가까워진다.
- 가중치에서 기울기를 빼도 값의 변화가 없을 때까지 계속해서 가중치 수정 작업을 반복하는 것!
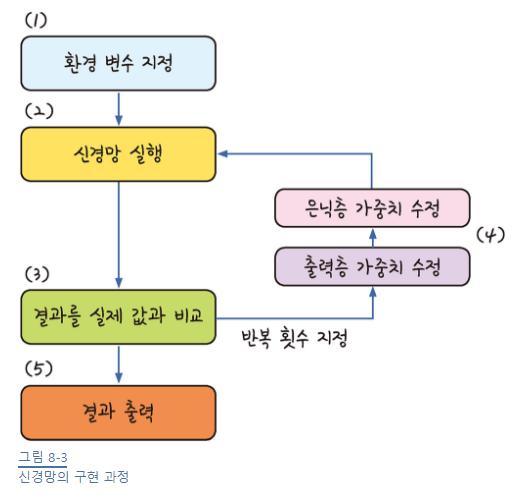
신경망에서 딥러닝으로
하지만 기대만큼 좋지는 않았다. 그 이유는 무엇이며, 어떻게 해결할까?
-
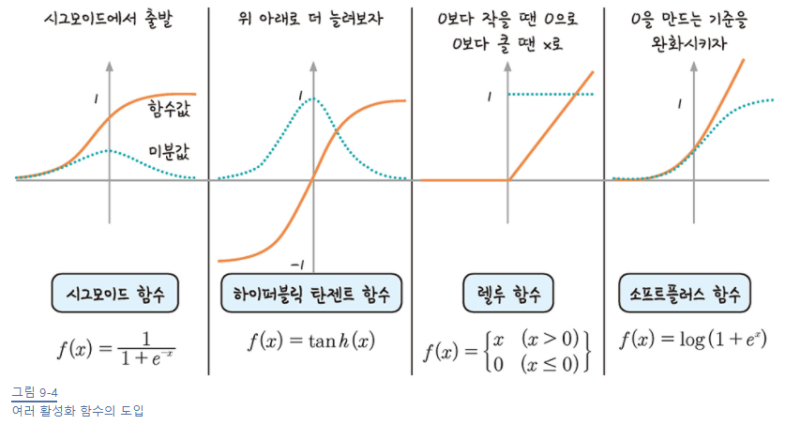
기울기 소실 문제와 활성화 함수
시그모이드 함수의 특성으로 인해 여러 층을 거칠수록 기울기가 사라져 가중치를 수정하기가 어렵다.
시그모이드 함수를 미분하면 최대치가 0.3
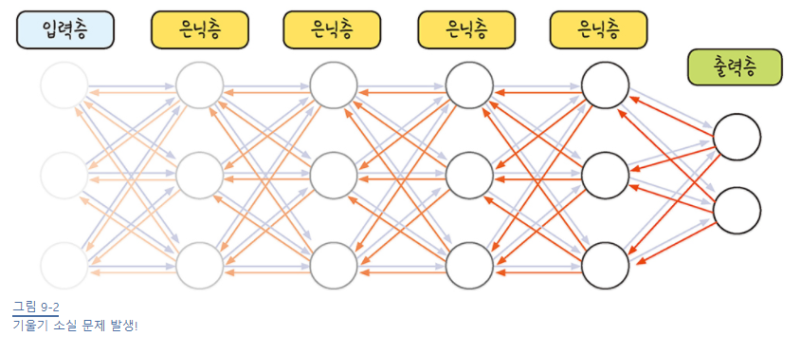
이런 문제로 활성화 함수를 다른 함수로 대체하려고 한다.
1) 하이퍼볼릭 탄젠트
- 미분한 값의 범위 확장되었지만 여전히 1보다 작은 값이 존재하여 기울기 소실 문제는 여전히 남아있다.
2) 렐루 (ReLU)
- x가 0보다 작을 때는 모든 값을 0, 0보다 큰 값은 x값 그대로 사용
- 단순해 보이지만, 이 방법을 쓰면 0보다 크기만 하면 미분값이 1이 된다.
이 간단한 방법이.. 여러 층을 쌓을 수 있게 했고, 딥러닝 발전에 속도가 붙는다! (이런….)
렐루의 0이 되는 순간을 완화한 소프트플러스(softplus) 함수를 개발 중이며, 좀 더 나은 활성화 함수를 만들기 위한 노력이 지금도 이어진다.
-
속도와 정확도 문제를 해결하는 고급 경사 하강법
한 번 업데이트할 때마다 전체 데이터를 미분해야 하므로 계산량이 너무 많다…ㅜ
이를 보완한 고급 경사 하강법이 등장하면서!!
딥러닝의 발전 속도는 더 빨라졌다…(천천히좀 가라)
1) 확률적 경사 하강법
-
전체 데이터를 사용하는게 아니라, 랜덤하게 추출한 일부 데이터를 사용
일부 데이터를 사용하니 자주 업데이트 하는 것이 가능해졌다.
-
중간 결과의 진폭이 크고 불안정해 보일 수 있으나 속도가 확연히 빠르며, 최적 해에 근사한 값을 찾아낸다.
2) 모멘텀
-
관성, 탄성, 관속도
-
매번 기울기를 구하지만, 오차를 수정하기 전에
바로 앞 수정 값과 방향(+,-)를 참고하여 같은 방향으로 일정한 비율만 수정되게 한다.
따라서, 수정 방향이 양수 한 번, 음수 한 번
즉, 지그재그로 일어나는 현상이 줄어들고, 이전 이동 값을 고려하여 일정 비율만큼만 다음 값을 결정하므로 관성의 효과를 낸다.
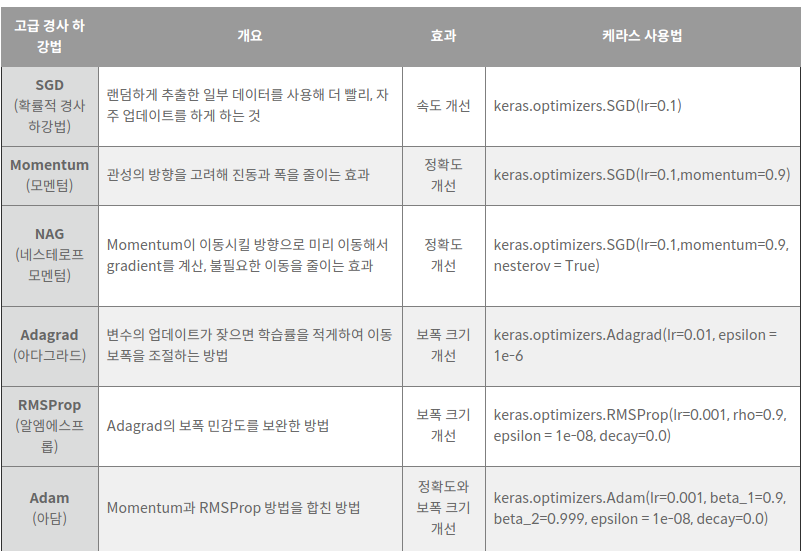
마지막의 Adam(아담)이 현재 가장 많이 사용되는 고급 경사 하강법!
-
4장. 딥러닝 기본기 다지기
실전에서 어떤 방식으로 구현되는지, 왜 그 어려운 개념들을 익혀야 했는지 공부할차례
맨 앞 코드를 설명 할 것입니다.
모델의 정의
예시 : 폐암 수술 환자의 생존율 예측하기
# 파일 선택을 통해 예제 데이터를 내 컴퓨터에서 불러옵니다.
from google.colab import files
uploaded = files.upload()
my_data = '/content/ThoraricSurgery.csv'
# 딥러닝을 구동하는 데 필요한 케라스 함수를 불러옵니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 필요한 라이브러리를 불러옵니다.
import numpy as np
import tensorflow as tf
# 실행할 때마다 같은 결과를 출력하기 위해 설정하는 부분입니다.
np.random.seed(3)
tf.random.set_seed(3)
# 불러온 데이터를 적용합니다.
Data_set = np.loadtxt(my_data, delimiter=",")
# 환자의 기록과 수술 결과를 X와 Y로 구분하여 저장합니다.
X = Data_set[:,0:17]
Y = Data_set[:,17]
# 딥러닝 구조를 결정합니다(모델을 설정하고 실행하는 부분입니다).
# 딥러닝의 구조를 짜고 층을 설정하는 부분
model = Sequential()
model.add(Dense(30, input_dim=17, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 딥러닝을 실행합니다.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 컴퓨터가 알아들을 수 있게 컴파일 한다.
model.fit(X, Y, epochs=100, batch_size=10)
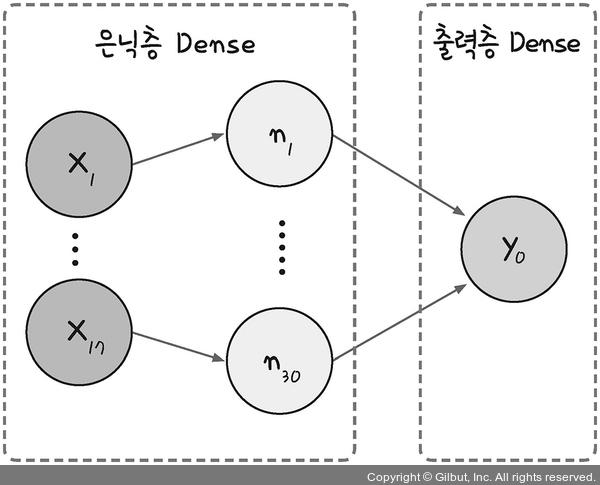
입력층, 은닉층, 출력층
model = Sequential()
model.add(Dense(30, input_dim=17, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
퍼셉트론 위에 숨겨진 퍼셉트론 층을 차곡차곡 추가하는 형태가 딥러닝
이 층들이 케라스에서 Sequential() 함수를 통해 쉽게 구현된다.
Sequential() 함수를 model로 선언하고, model.add()을 추가하면 새로운 층이 만들어진다.
model.add()로 시작되는 라인이 두 개이므로, 두 개의 층을 가진 모델을 만든 것!
맨 마지막 층은 출력층이고, 나머지는 모두 은닉층 역할이겠지?
그렇다면 위 두개의 층은 각각 은닉층과 출력층이겠네
Dense라는 함수로 그 구조가 구체적으로 결정되는데 어떤 의미냐?
17개의 값을 받아 은닉층의 30개 노드로 보낸다.
Dense(30, input_dim=17, activation=’relu’)
이 층에 30 개의 노드를 만들겠다.
input_dim : 입력 데이터에서 17개의 값을 가져 오겠다.
keras는 입력층을 따로 만드는 것이 아니라, 첫번째 Dense가 은닉층 + 입력층 역할을 한다.
활성화 함수는 relu!
Dense(1, activation=’sigmoid’)
마지막 층이므로 출력층이겠네
당연한 소리지만 출력 값을 하나로 보내므로 출력층의 노드 수는 1개
여기서 활성화 함수는 시그모이드
모델 컴파일
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
어떤 오차 함수(loss function)를 사용할지?
최적화 : adam
metrics : 모델이 컴파일될 때 모델 수행 결과를 나타내게끔 설정하는 부분
정확도를 측정하기 위해 사용되는 테스트 샘플을 학습 과정에서 제외시켜 overfitting을 방지한다.
참고 : https://keras.io/api/losses/
-
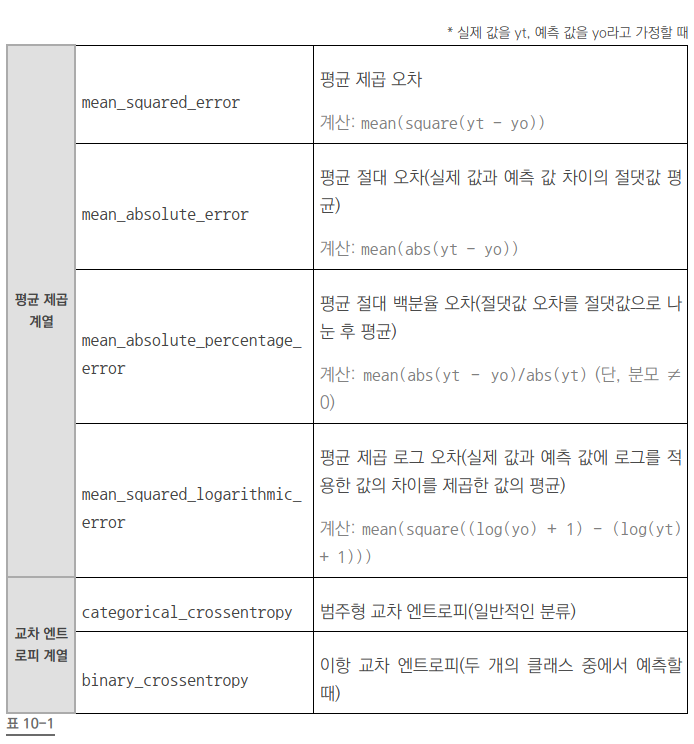
평균 제곱 오차 함수 (mean_sqaured_error)
수렴하기까지 속도가 많이 걸리는 단점이 있다.
-
교차 엔트로피 함수 (cross entropy)
출력값에 로그를 취해서, 오차가 커지면 수렴 속도가 빨라지고 오차가 작아지면 수렴 속도가 감소한다.
-
이항 교차 엔트로피 함수 (binary_crossentropy)
교차 엔트로피
주로 분류 문제에 많이 사용된다.
예측 값이 참과 거짓 둘 중 하나 일때는 binary_crossentropy(이항교차 엔트로피)를 쓴다.
위 예제는 생존(1) 또는 사망(0)이므로 좋은 방법.
모델 실행하기
model.fit(X, Y, epochs=100, batch_size=10)
-
epoch=100
각 샘플이 처음부터 끝까지 100번 재사용될때까지 실행을 반복
-
batch_size=10
전체 샘플을 10개씩 끊어서 집어넣어라
batch_size가 너무 크면 학습속도가 느려지고, 너무 작으면 전체 결과값이 불안정해진다.
따라서, 자신의 컴퓨터 메모리가 감당할 만큼의 batch_size를 지정하자!
-
전체 2000 개의 데이터가 있고, epochs = 20, batch_size = 500이라고 가정.
그렇다면 1 epoch는 각 데이터의 size가 500인 batch가 들어간 네 번의 iteration으로 나누어 짐.
그리고 전체 데이터셋에 대해서는 20 번의 학습이 이루어졌으며, iteration 기준으로 보자면 총 80 번의 학습이 이루어진 것!
딥러닝과 데이터
당연한 소리지만, 좋은 결과를 얻기 위해서 양보단 질이다.
좋은 데이터란 내가 알아내고자 하는 정보를 잘 담고 있는 데이터.
이제부터 딥러닝 실습을 해볼건데 모든 실습은 데이터를 분석하고 조사하는 것부터 시작이다!
파이썬 라이브러리인 pandas와 matplotlib를 사용하여 데이터가 어떤 내용을 담고 있는지 확인해보자.
pandas를 활용한 데이터 조사
-
피마 인디언 데이터 분석하기
# -*- coding: utf-8 -*- # 코드 내부에 한글을 사용가능 하게 해주는 부분입니다. # pandas 라이브러리를 불러옵니다. import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 피마 인디언 당뇨병 데이터셋을 불러옵니다. 불러올 때 각 컬럼에 해당하는 이름을 지정합니다. df = pd.read_csv('../dataset/pima-indians-diabetes.csv', names = ["pregnant", "plasma", "pressure", "thickness", "insulin", "BMI", "pedigree", "age", "class"])헤더 : 데이터를 설명하는 맨 첫줄 ==> 여기서는 names
데이터를 보고 싶으면 아래와 같이!
# 처음 5줄을 봅니다. print(df.head(5)) # 데이터의 전반적인 정보를 확인해 봅니다. print(df.info()) # 각 정보별 특징을 좀더 자세히 출력합니다. print(df.describe()) # 데이터 중 임신 정보와 클래스 만을 출력해 봅니다. print(df[['plasma', 'class']])
데이터 가공하기
많은 데이터를 단순히 나열만 하는 것은 의미가 없지
한번 더 가공해야해
가공하기전에 무엇을 위해 작업하는지 목적을 잊어서는 안된다!
예제의 목적은 당뇨병 발병을 예측하는 것
print(df[['pregnant', 'class']].groupby(['pregnant'], as_index=False).mean().sort(by='pregnant', ascending=True))
groupby → pregnant 정보를 기준으로 하는 새 그룹을 만든다.
as_index=Fase → pregnant 정보 옆에 새로운 인덱스를 만든다.
mean() → 평균을 구하고
sort_values() → pregnant 결과를 오름차순으로 정렬한다.
matplotlib를 이용해 그래프로 표현하기
그래프로 표현해서 데이터 성격을 파악해보자
좀 더 정확한 그래프를 그리기 위해 seaborn 라이브러리를 사용해보자
import matplotlib.pyplot as plt
import seaborn as sns
colormap = plt.cm.gist_heat #그래프의 색상 구성을 정합니다.
plt.figure(figsize=(12,12)) #그래프의 크기를 정합니다.
# 그래프의 속성을 결정합니다. vmax의 값을 0.5로 지정해 0.5에 가까울 수록 밝은 색으로 표시되게 합니다.
sns.heatmap(df.corr(),linewidths=0.1,vmax=0.5, cmap=colormap, linecolor='white', annot=True)
plt.show()
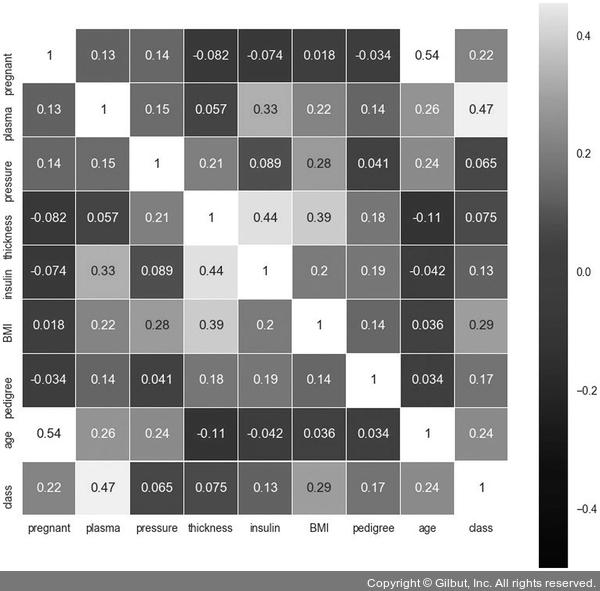
당뇨병 발병 여부를 가리키는 class 항목과 가장 상관관계가 높은 항목은 plasma
(숫자가 높을수록 밝은 색상)
plasma와 class 항목만 따로 떼어내서 그래프로 확인해보자
grid = sns.FacetGrid(df, col='class')
grid.map(plt.hist, 'plasma', bins=10)
plt.show()
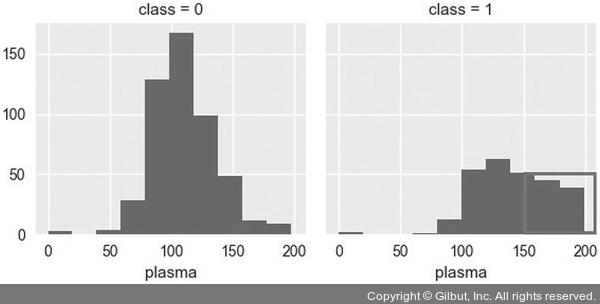
당뇨병 환자의 경우 plasma 항목의 수치가 150 이상인 경우가 많다.
잃게 결과에 미치는 영향이 큰 항목을 발견하는 것이 데이터 전처리 과정의 한 예이다.
이 과정은 머신러닝의 성능 향상에 중요한 역할을 한다!
피마 인디언의 당뇨병 예측 실행
# 딥러닝을 구동하는 데 필요한 케라스 함수를 불러옵니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 필요한 라이브러리를 불러옵니다.
import numpy
import tensorflow as tf
# 실행할 때마다 같은 결과를 출력하기 위해 설정하는 부분입니다.
numpy.random.seed(3)
tf.random.set_seed(3)
# 데이터를 불러 옵니다.
dataset = numpy.loadtxt("../dataset/pima-indians-diabetes.csv", delimiter=",")
X = dataset[:,0:8]
Y = dataset[:,8]
# 모델을 설정합니다.
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델을 컴파일합니다.
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 모델을 실행합니다.
model.fit(X, Y, epochs=200, batch_size=10)
# 결과를 출력합니다.
print("\n Accuracy: %.4f" % (model.evaluate(X, Y)[1]))
-
seed 값 생성
np.random.seed(seed) tf.random.set_seed(seed)seed값 설정한다?
랜덤 테이블 중 몇 번째 테이블을 불러와 쓸지 정하겠다.
seed값이 같으면 똑같은 랜덤 값을 출력한다.
-
모델 설정
# 모델을 설정합니다. model = Sequential() model.add(Dense(12, input_dim=8, activation='relu')) model.add(Dense(8, activation='relu')) model.add(Dense(1, activation='sigmoid'))은닉층을 add함수를 통해 하나 더 추가하였다.
다중 분류 문제
여러 개의 답 중 하나를 고르는 분류 문제인데
둘 중 하나를 고르는 이항 분류(binary classification)와는 다르다.
예제는 아이리스의 품종을 예측하는 프로그램이다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.preprocessing import LabelEncoder
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
# seed 값 설정
np.random.seed(3)
tf.random.set_seed(3)
# 데이터 입력
df = pd.read_csv(’../dataset/iris.csv’, names = [“sepal_length”, “sepal_width”, “petal_length”, “petal_width”, “species”])
# 그래프로 확인
sns.pairplot(df, hue=‘species’);
plt.show()
# 데이터 분류
dataset = df.values
X = dataset[:,0:4].astype(float)
Y_obj = dataset[:,4]
# 문자열을 숫자로 변환
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
Y_encoded = tf.keras.utils.to_categorical(Y)
# 모델의 설정
model = Sequential()
model.add(Dense(16, input_dim=4, activation=‘relu’))
model.add(Dense(3, activation=‘softmax’))
# 모델 컴파일
model.compile(loss=‘categorical_crossentropy’, optimizer=‘adam’, metrics=[‘accuracy’])
# 모델 실행
model.fit(X, Y_encoded, epochs=50, batch_size=1)
# 결과 출력
print(“\n Accuracy: %.4f” % (model.evaluate(X, Y_encoded)[1]))
정확도 : 98.67%
-
상관도 그래프
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from sklearn.preprocessing import LabelEncoder import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import numpy as np import tensorflow as tf # 실행할 때마다 같은 결과를 출력하기 위해 설정하는 부분입니다. np.random.seed(3) tf.random.set_seed(3) # 데이터 입력 df = pd.read_csv('../dataset/iris.csv', names = ["sepal_length", "sepal_width", "petal_length", "petal_width", "species"]) # 그래프로 확인 sns.pairplot(df, hue='species'); plt.show()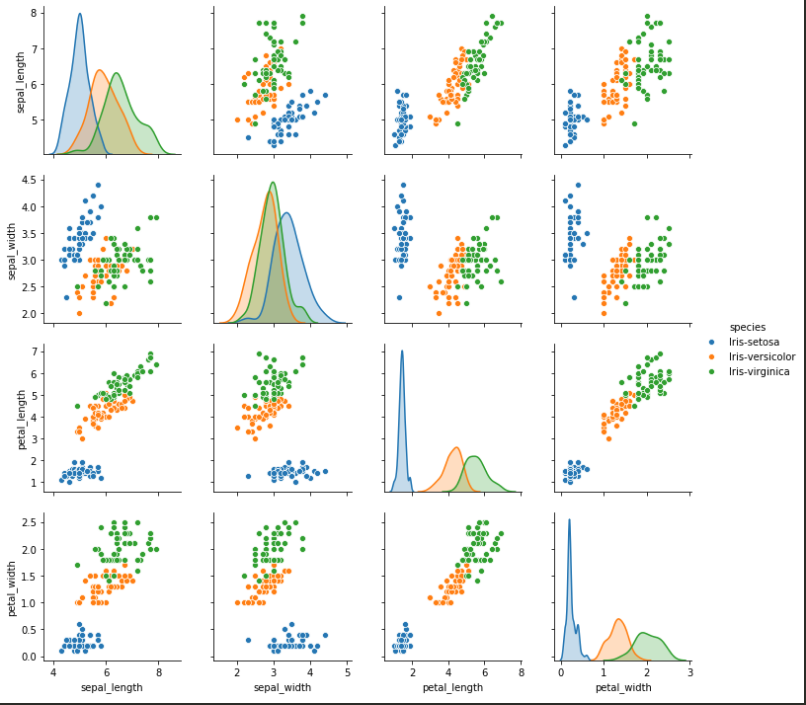
속성별로 어떤 연관이 있는지 보면 프로젝트의 감을 잡을 수 있다.
원-핫 인코딩
데이터 안에 문자열이 포함되어 있으면 어떻게 처리할까?
numpy보다는 pandas로 데이터를 불러와 X와 Y 값을 구분하자.
# 데이터 입력
df = pd.read_csv('../dataset/iris.csv', names = ["sepal_length", "sepal_width", "petal_length", "petal_width", "species"])
# 데이터 분류
dataset = df.values
X = dataset[:,0:4].astype(float)
Y_obj = dataset[:,4]
Y값이 숫자가 아니라 문자열이다.
문자열을 숫자로 바꿔주려면 클래스 이름을 숫자 형태로 바꿔줘야 하는데
sklearn 라이브러리의 LabelEncoder() 함수를 사용하자.
# 문자열을 숫자로 변환
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
이렇게 하면 array([‘Iris-setosa’, ‘Iris-versicolor’, ‘Iris-virginica’])가 array([1,2,3])
으로 바뀐다.
또한, 활성화 함수를 적용하려면 Y값이 0과 1로 이루어져 있어야 하는데 tf.kreas.utils.categorical() 함수를 적용하자
Y_encoded = tf.keras.utils.to_categorical(Y)
그러면 array([1,2,3])가 array([[1., 0., 0.], [0., 1., 0.], [0., 0., 1.]])
이처럼 여러 개의 Y값을 0과 1로만 이루어진 형태로 바꿔주는 기법을 원-핫 인코딩이라고 한다.
소프트맥스
# 모델의 설정
model = Sequential()
model.add(Dense(16, input_dim=4, activation='relu'))
model.add(Dense(3, activation='softmax'))
최종 출력값이 3개 중 하나이므로 Dense의 노트 수는 3으로 설정
활성화 함수로는 softmax 이용

과적합 피하기
음파 탐지기 데이터 정보를 이용해 광물과 돌을 구분하는 실험
from keras.models import Sequential
from keras.layers.core import Dense
from sklearn.preprocessing import LabelEncoder
import pandas as pd
import numpy
import tensorflow as tf
# seed 값 설정
numpy.random.seed(3)
tf.random.set_seed(3)
# 데이터 입력
df = pd.read_csv('../dataset/sonar.csv', header=None)
'''
# 데이터 개괄 보기
print(df.info())
# 데이터의 일부분 미리 보기
print(df.head())
'''
dataset = df.values
X = dataset[:,0:60]
Y_obj = dataset[:,60]
# 문자열 변환
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
# 모델 설정
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model.compile(loss='mean_squared_error',
optimizer='adam',
metrics=['accuracy'])
# 모델 실행
model.fit(X, Y, epochs=200, batch_size=5)
# 결과 출력
print("\n Accuracy: %.4f" % (model.evaluate(X, Y)[1]))
결과 Accuracy가 100이 나오는데 정말 정확도가 100일까?
-
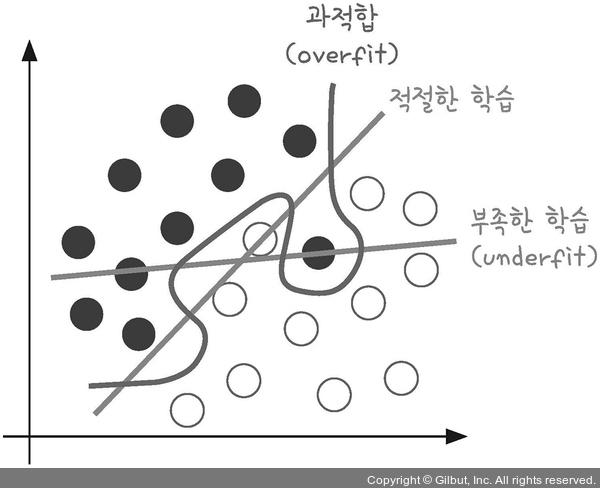
과적합(overfitting) 이해하기
과적합이란?
모델이 학습 데이터셋 안에서는 일정 수준 이상의 예측 정확도를 보이지만, 새로운 데이터에 적용하면 잘 맞지 않는것
층이 너무 많거나 변수가 복잡해서 발생하기도 하고 테스트셋과 학습셋이 중복될 때 생기기도 한다.
-
학습셋과 데이터셋
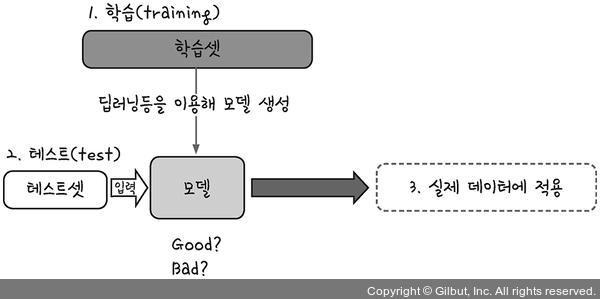
과적합을 방지하려면 어떻게 해야할까?
학습 데이터셋과 테스트 데이터셋을 완전히 구분한 다음
학습과 동시에 테스트를 병행하여 진행하자!

70개의 샘플로 학습을 진행한 후 이 결과를 저장한 파일을 모델
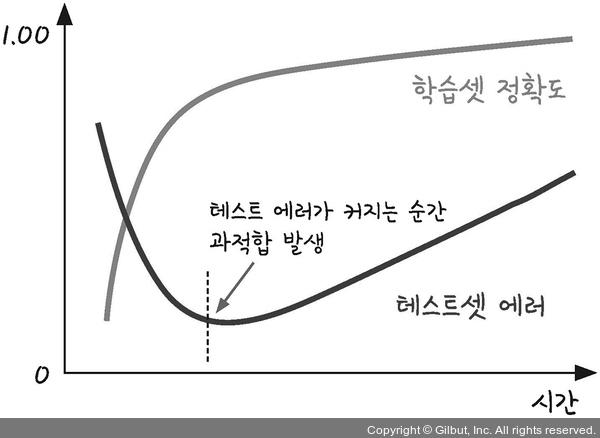
은닉층이 늘어날수록 학습셋의 예측률이 점점 올라 결국 100프로의 예측률을 보이지만
테스트셋 예측률은 오히려 떨어지는 경우가 있다.
한 그룹은 학습에, 한 그룹은 테스트에 사용하게 하는 함수가
sklearn 라이브러리의 train_test_split() 함수이다.
다시 한번 진행해보자.
from keras.models import Sequential
from keras.layers.core import Dense
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy
import tensorflow as tf
# seed 값 설정
seed = 0
numpy.random.seed(seed)
tf.random.set_seed(3)
df = pd.read_csv('../dataset/sonar.csv', header=None)
'''
print(df.info())
print(df.head())
'''
dataset = df.values
X = dataset[:,0:60]
Y_obj = dataset[:,60]
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
# 학습 셋과 테스트 셋의 구분
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=seed)
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='mean_squared_error',
optimizer='adam',
metrics=['accuracy'])
model.fit(X_train, Y_train, epochs=130, batch_size=5)
# 테스트셋에 모델 적용
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, Y_test)[1]))
결과는 0.8095 이며 앞에서 나온 100%와 비교하면 차이가 나네.
# 학습 셋과 테스트 셋의 구분
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=seed)
학습과 테스트 셋을 나누어 아래와 같이 진행한다.
model.fit(X_train, Y_train, epochs=130, batch_size=5)
# 테스트셋에 모델 적용
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, Y_test)[1]))
-
모델 저장과 재사용
학습한 결과를 모델로 저장하고 재 사용해본다.
from keras.models import Sequential, load_model from keras.layers.core import Dense from sklearn.preprocessing import LabelEncoder import pandas as pd import numpy import tensorflow as tf # seed 값 설정 seed = 0 numpy.random.seed(seed) tf.random.set_seed(3) df = pd.read_csv('../dataset/sonar.csv', header=None) ''' print(df.info()) print(df.head()) ''' dataset = df.values X = dataset[:,0:60] Y_obj = dataset[:,60] e = LabelEncoder() e.fit(Y_obj) Y = e.transform(Y_obj) # 학습셋과 테스트셋을 나눔 from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=seed) model = Sequential() model.add(Dense(24, input_dim=60, activation='relu')) model.add(Dense(10, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy']) model.fit(X_train, Y_train, epochs=130, batch_size=5) model.save('my_model.h5') # 모델을 컴퓨터에 저장 del model # 테스트를 위해 메모리 내의 모델을 삭제 model = load_model('my_model.h5') # 모델을 새로 불러옴 print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, Y_test)[1])) # 불러온 모델로 테스트 실행 -
k겹 교차 검증
데이터가 충분치 않으면 좋은 결과를 내기가 어렵다..
약 70프로가 학습셋, 30프로가 테스트셋인데 겨우 전체 데이터의 30%..
실제로 얼마나 잘 작동하는지 확신하기는 쉽지 않다.
이 단점을 보완하기 위해 K겹 교차 검증(k-fold cross validation) 이용
데이터셋을 여러개로 나누어 하나씩 테스트셋으로 사용하고 나머지를 모두 합해서 학습셋으로 사용하는 방법.
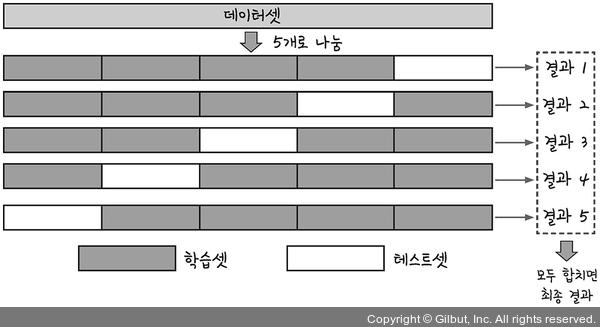
이렇게 하면 가지고 있는 데이터의 100%를 테스트셋으로 사용할 수 있겠지?
sklearn의 StratifiedKFold() 함수를 이용하자.
from keras.models import Sequential from keras.layers.core import Dense from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import StratifiedKFold import numpy import pandas as pd import tensorflow as tf # seed 값 설정 seed = 0 numpy.random.seed(seed) tf.random.set_seed(3) df = pd.read_csv('../dataset/sonar.csv', header=None) dataset = df.values X = dataset[:,0:60] Y_obj = dataset[:,60] e = LabelEncoder() e.fit(Y_obj) Y = e.transform(Y_obj) # 10개의 파일로 쪼갬 n_fold = 10 skf = StratifiedKFold(n_splits=n_fold, shuffle=True, random_state=seed) # 빈 accuracy 배열 accuracy = [] # 모델의 설정, 컴파일, 실행 for train, test in skf.split(X, Y): model = Sequential() model.add(Dense(24, input_dim=60, activation='relu')) model.add(Dense(10, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy']) model.fit(X[train], Y[train], epochs=100, batch_size=5) k_accuracy = "%.4f" % (model.evaluate(X[test], Y[test])[1]) accuracy.append(k_accuracy) # 결과 출력 print("\n %.f fold accuracy:" % n_fold, accuracy) >> 10 fold accuracy: ['0.8182', '0.7143', '0.8095', '0.8095', '0.7619', '0.8095', '0.8571', '0.9500', '0.7500', '0.8000']